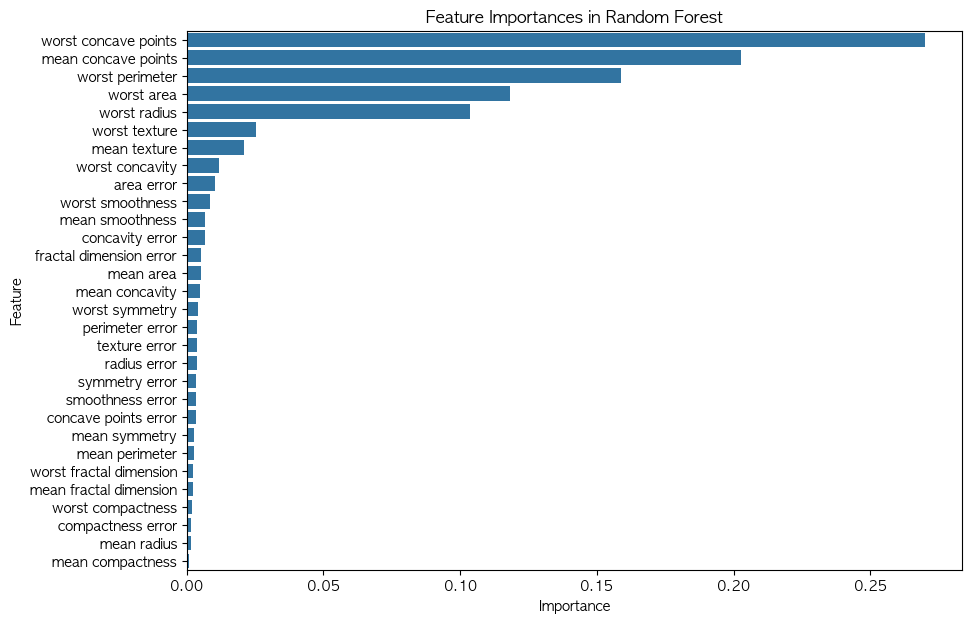
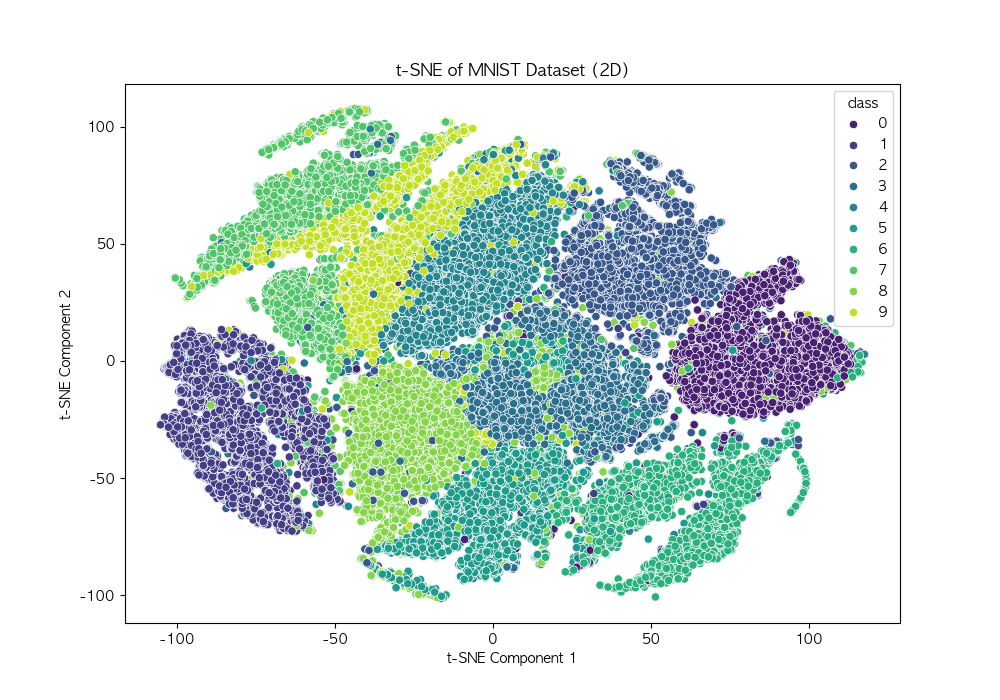
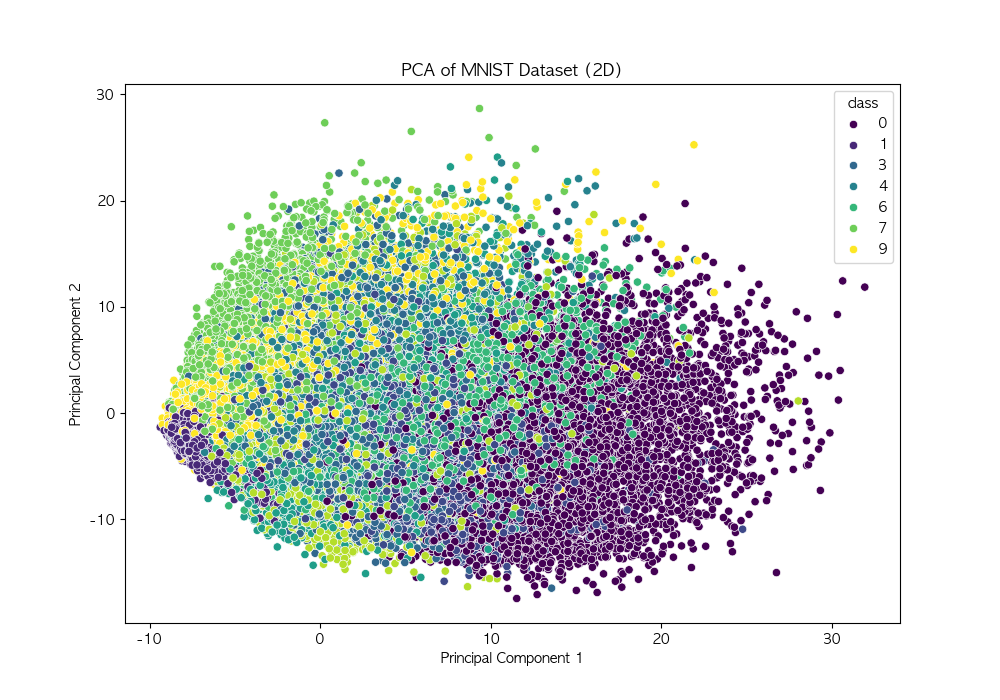
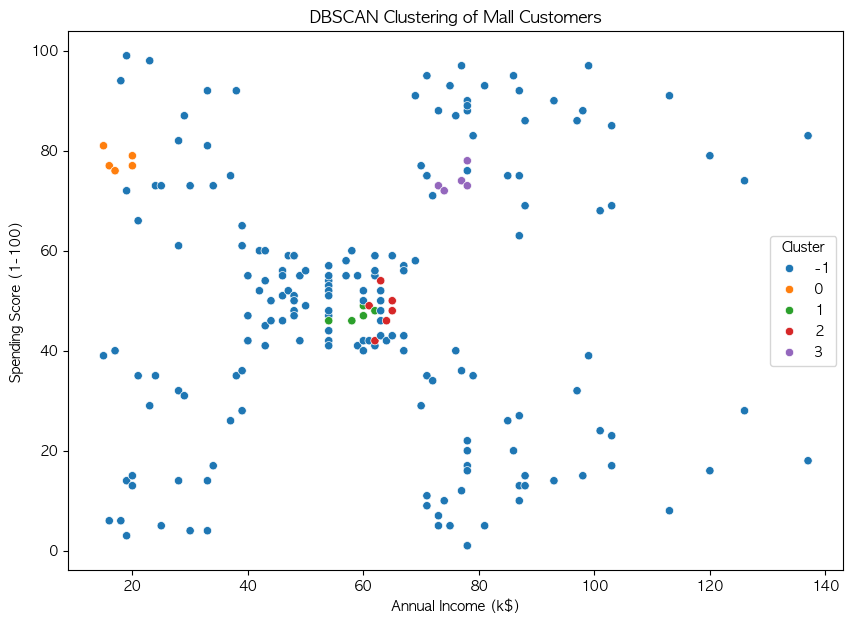
딥러닝(Deep Learning) 인공신경망(Artificial Neural Networks, ANN)을 기반으로 한 기계 학습(Machine Learning)의 한 분야 여러 층(layer)으로 구성된 신경망을 통해 데이터에서 중요한 특징을 자동으로 학습하고, 합습을 바탕으로 예측, 분류, 생성 등의 다양한 작업을 수행기존 머신러닝과 달리 특징 공학(feature engineering)과정이 필요 없이, 데이터로부터 직접 패턴을 학습 비선형 추론 가능 : 다층 구조를 활용해 복잡한 데이터의 패턴 학습 가능자동 특징 추출 : 별도의 특징 엔지니어링 없이도 데이터에서 유의미한 특징을 찾아낼 수 있음대용량 데이터 학습 : GPU연산을 활용하여 대량의 데이터를 빠르게 처리하고 학습 가능다양한 응용 가능 : 이..