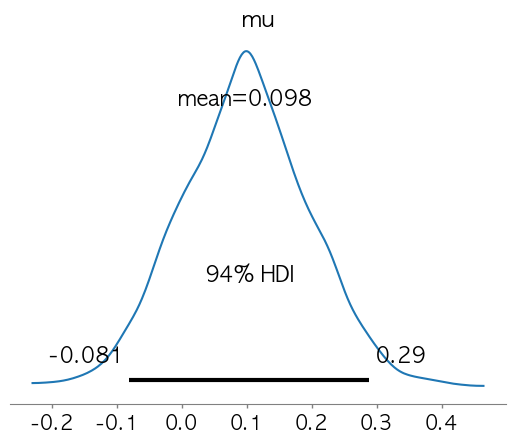
베이즈 정리와 사전/사후 확률 베이즈 정리는 기존의 사전 확률을 새로운 증거를 바탕으로 갱신하여 사후 확률을 계산하는 방법을 제공→ 통계적 추론, 머신러닝, 의학적 진단 등 다양한 분야에서 활용 베이즈 정리P(A|B) = P(B|A) * P(A) / {P(B) 사전 확률 (Prior Probability, (P(A))): 새로운 정보를 얻기 전 특정 사건 (A) 가 발생할 확률우도 (Likelihood, (P(B|A))): 사건 (A) 가 발생했을 때 증거 (B) 가 나타날 확률사후 확률 (Posterior Probability, (P(A|B))): 증거 (B) 가 주어졌을 때 사건 (A) 가 발생할 확률증거 (Evidence, (P(B))): 증거 (B) 가 발생할 전체 확률 활용 사례조건부 확률 계산..