DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
밀도 기반 군집화 알고리즘
데이터 밀도가 높은 영역을 군집으로 간주하고, 밀도가 낮은 영역을 노이즈로 처리
- 비구형 군집 탐지 가능 : 원형이 아닌 군집도 효과적으로 탐색 가능
- 노이즈 처리 가능 : 밀도가 낮은 데이터 포인트를 자동으로 노이즈로 분류
- 군집 수 자동 결정 : 군집 개수를 미리 설정할 필요 없음
주요 매개변수
- eps : 두 데이터 포인트가 같은 군집에 속하기 위한 최대 거리
- min_samples : 한 군집을 형성하기 위해 필요한 최소 데이터 포인트 수
작동원리
- 임의의 데이터 포인트 선택
- 선택한 데이터 포인트의 eps 반경 내에 있는 모든 데이터 포인트를 찾음
- eps 반경 내 데이터 수가 min_samples 이상이면 새로운 군집 형성
- eps 반경 내 데이터 수가 min_samples 미만이면 노이즈로 간주
- 군집에 속한 데이터 포인트에 대해 2~4단계를 반복
- 모든 데이터가 처리될 때까지 반복
DBSCAN 실습
Kaggle의 쇼핑몰 고객 데이터(Mall_Customers.csv)를 사용하여 실습 진행
데이터 로드
import kagglehub
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
path = kagglehub.dataset_download("vjchoudhary7/customer-segmentation-tutorial-in-python")
# 데이터 파일 경로 생성
csv_path = os.path.join(path, "Mall_Customers.csv")
# 데이터셋 불러오기
df = pd.read_csv(csv_path)
# 필요한 열만 선택
X = df[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']]
DBSCAN 군집화 수행
from sklearn.cluster import DBSCAN
import seaborn as sns
# DBSCAN 모델 생성
dbscan = DBSCAN(eps=5, min_samples=5)
# 모델 학습 및 예측
df['Cluster'] = dbscan.fit_predict(X)
# 군집화 결과 시각화
plt.figure(figsize=(10, 7))
sns.scatterplot(x='Annual Income (k$)', y='Spending Score (1-100)', hue='Cluster', data=df, palette='viridis')
plt.title('DBSCAN Clustering of Mall Customers')
plt.show()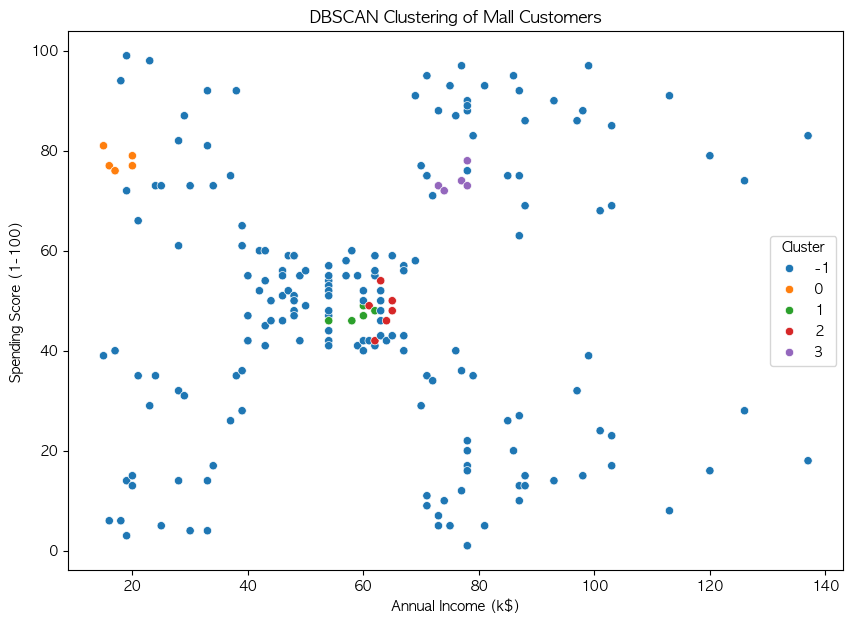
파라미터 튜닝
DBSCAN의 성능은 eps와 min_samples 값에 따라 크게 달라짐
여러 값을 시도하여 적절한 파라미터를 찾음
# 다양한 eps와 min_samples 값 시도
eps_values = [3, 5, 7, 10]
min_samples_values = [3, 5, 7, 10]
for eps in eps_values:
for min_samples in min_samples_values:
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
df['Cluster'] = dbscan.fit_predict(X)
plt.figure(figsize=(10, 7))
sns.scatterplot(x='Annual Income (k$)', y='Spending Score (1-100)', hue='Cluster', data=df, palette='viridis')
plt.title(f'DBSCAN Clustering (eps={eps}, min_samples={min_samples})')
plt.show()

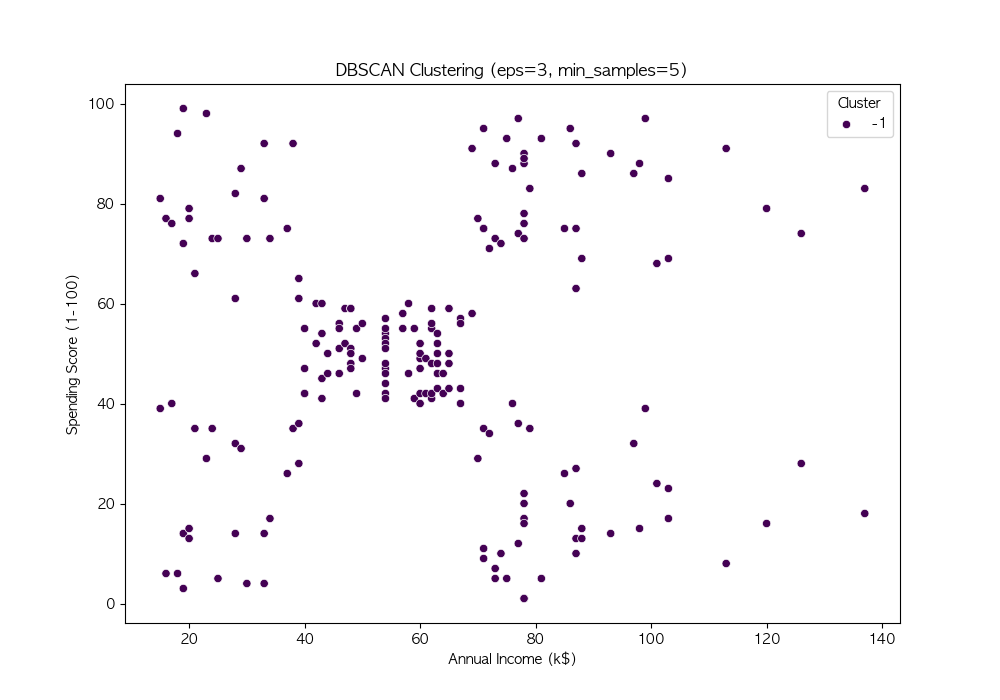
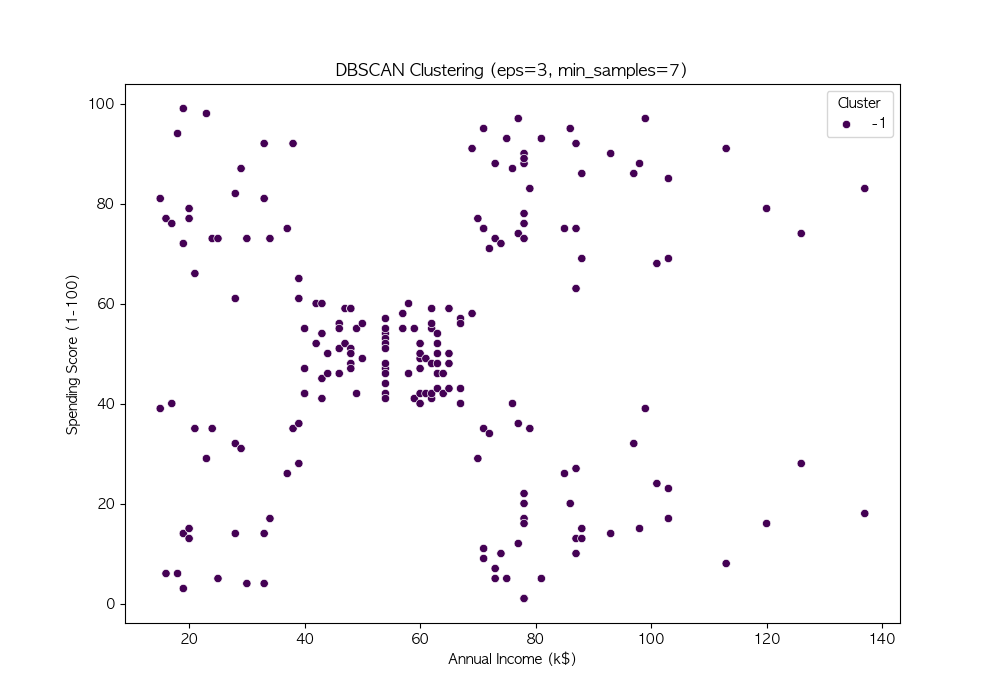
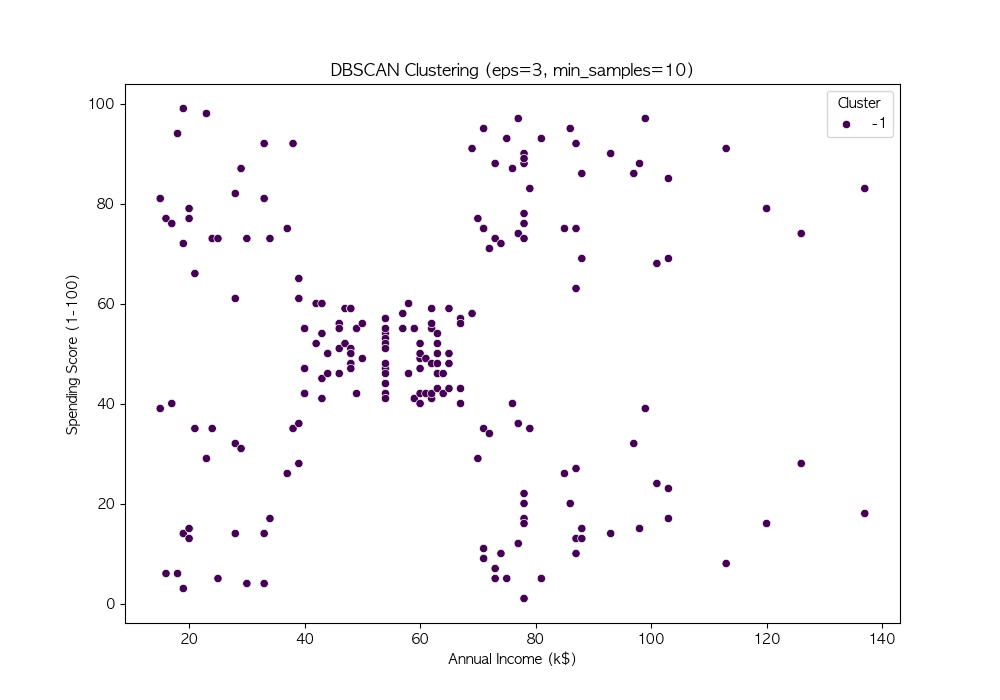
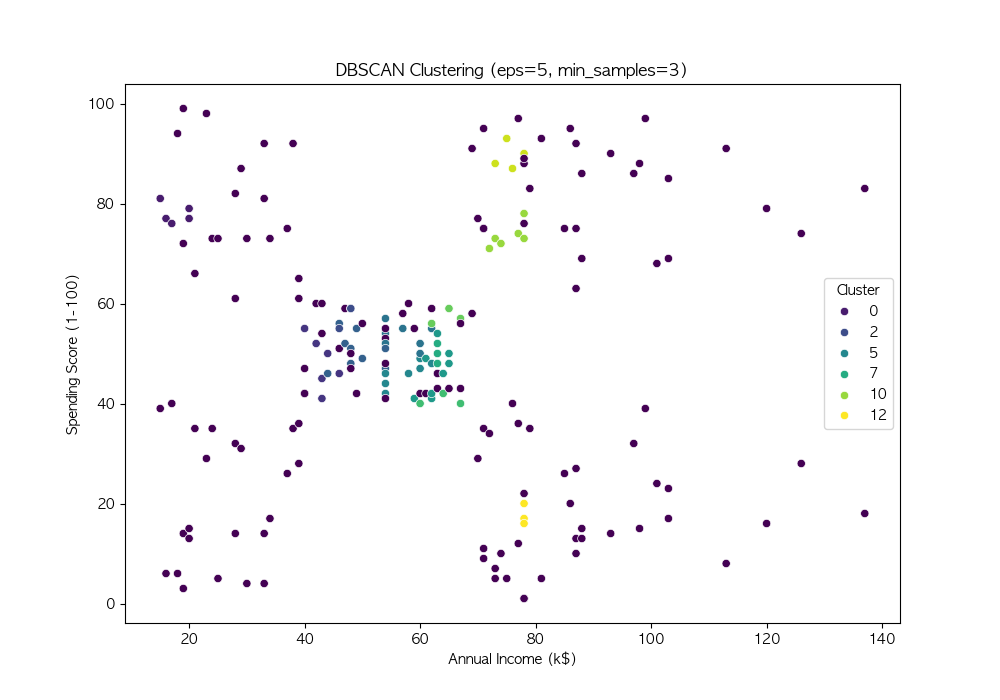
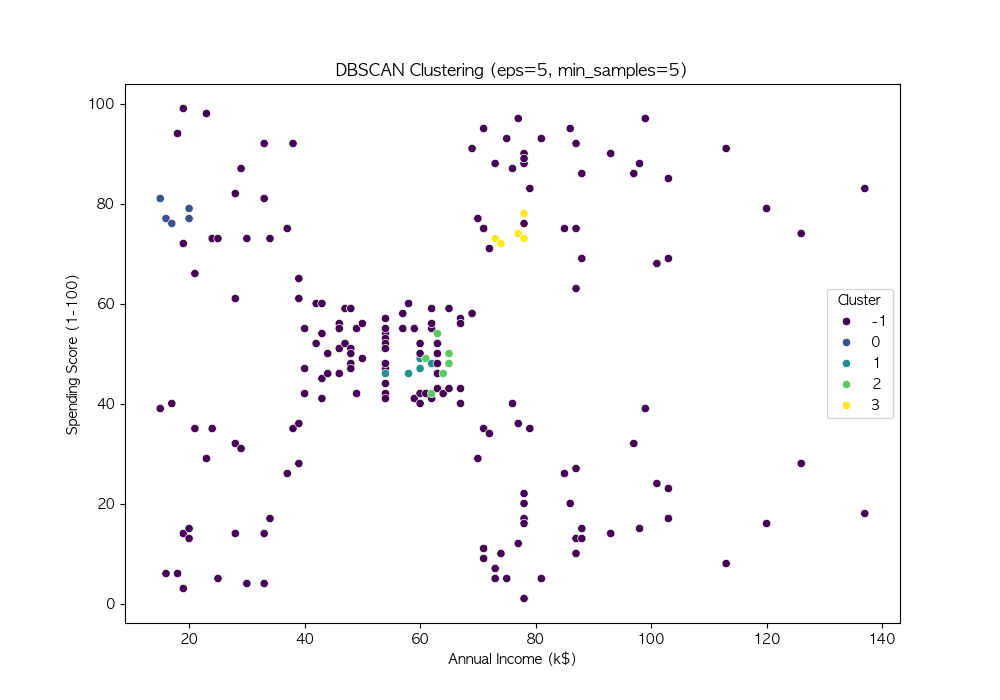
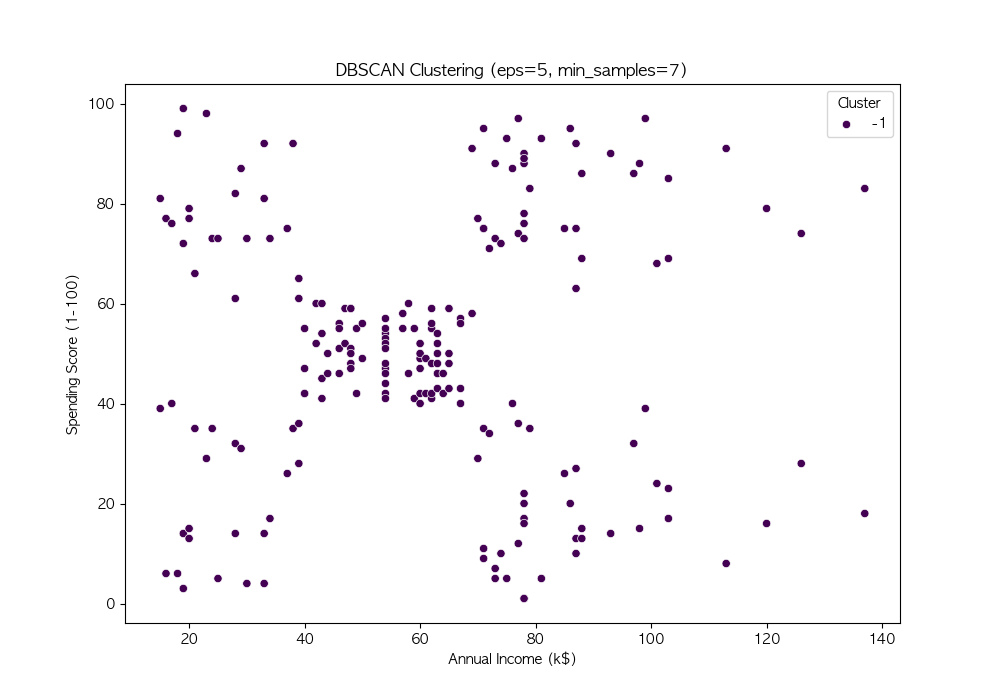
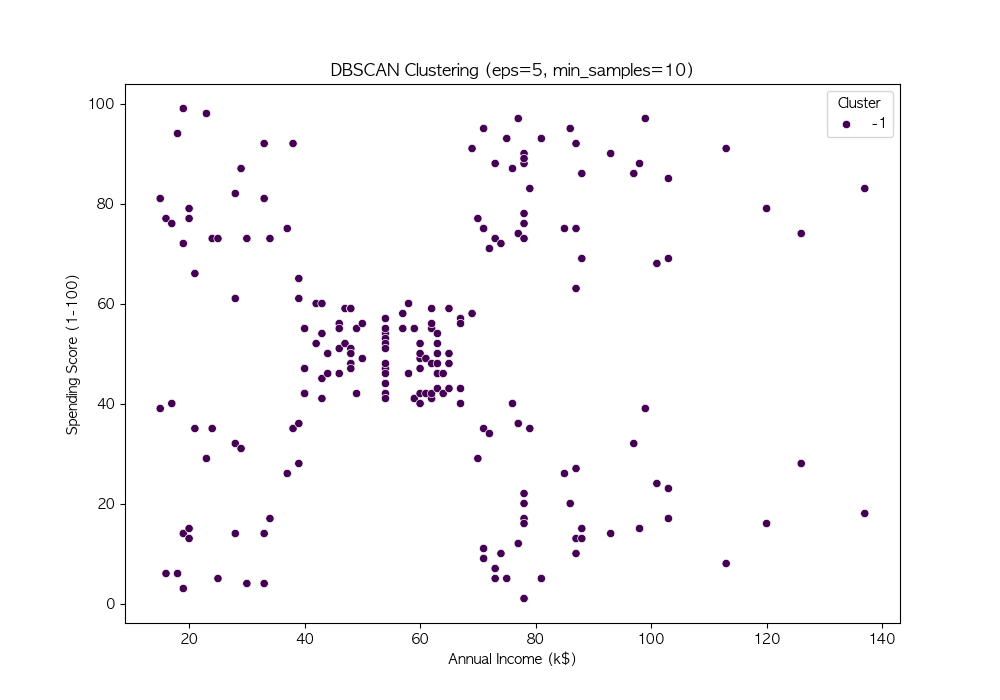
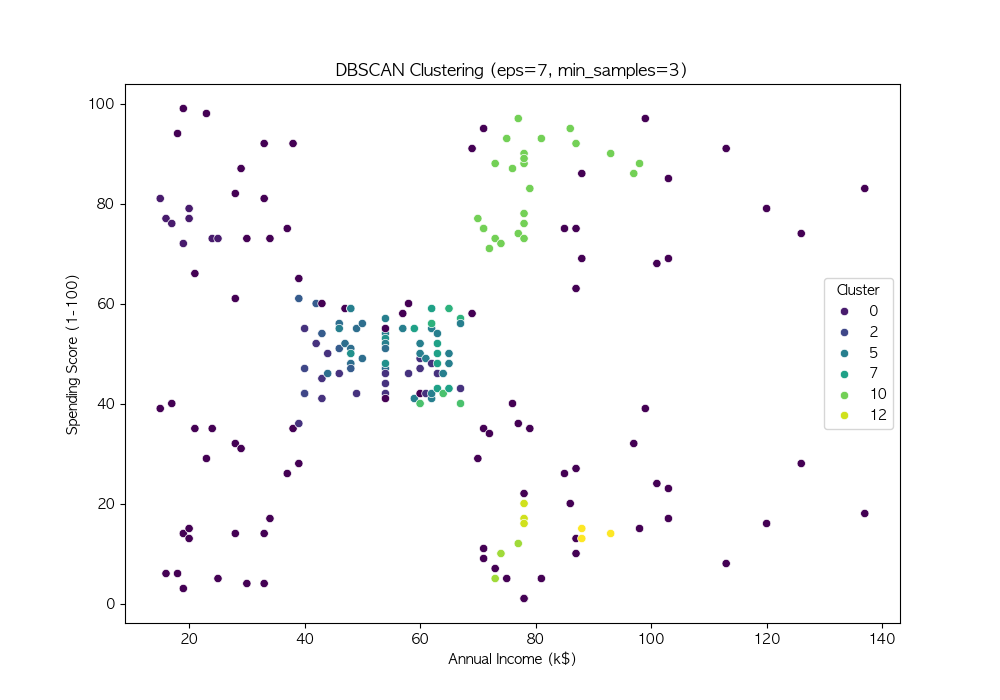
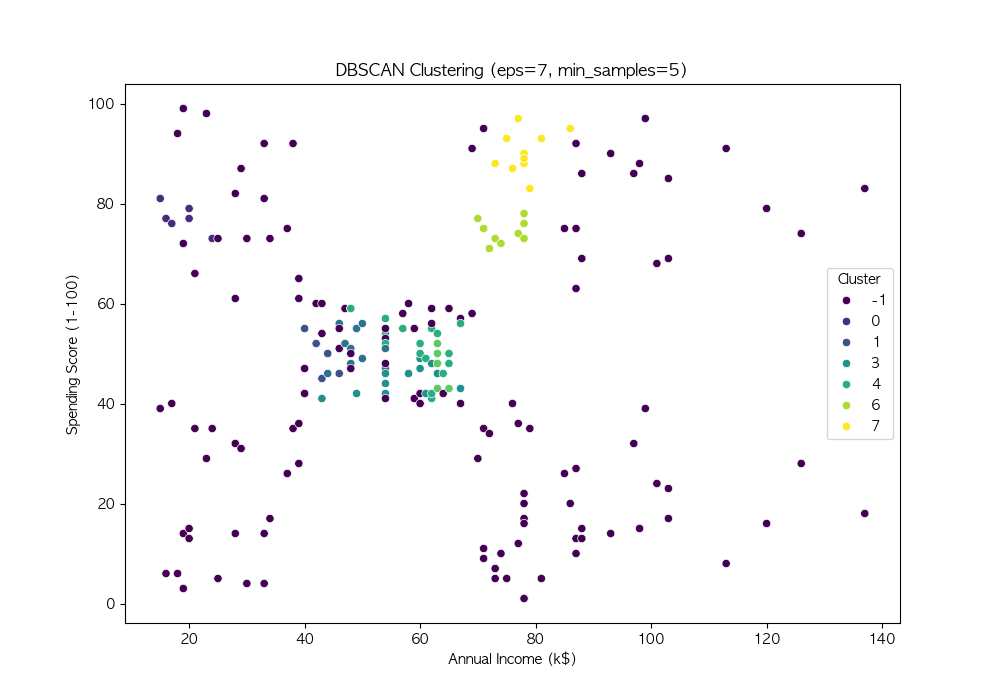
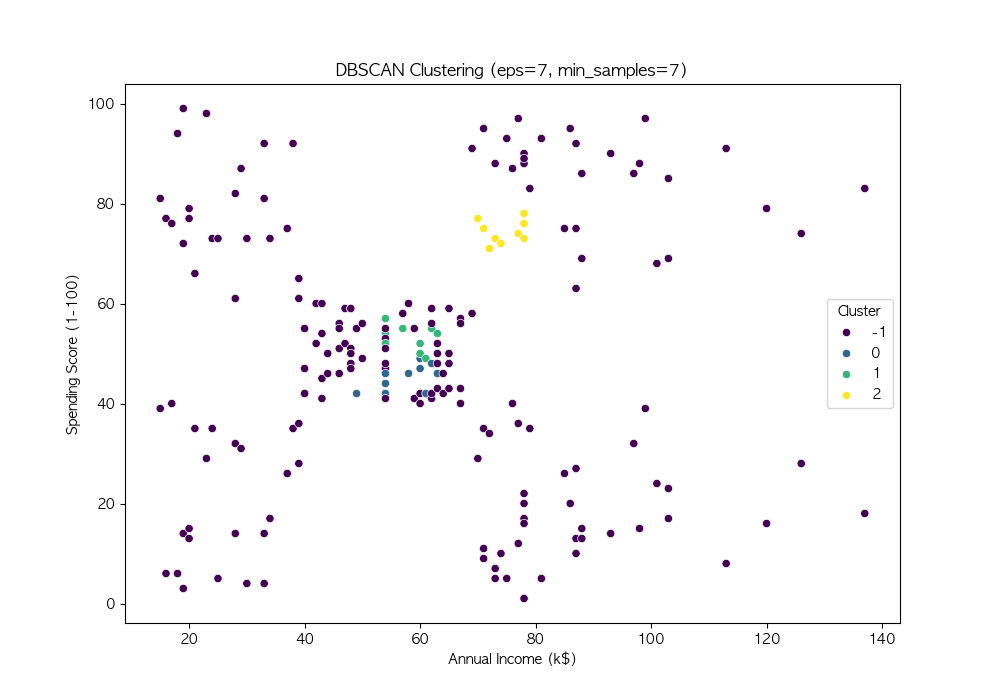
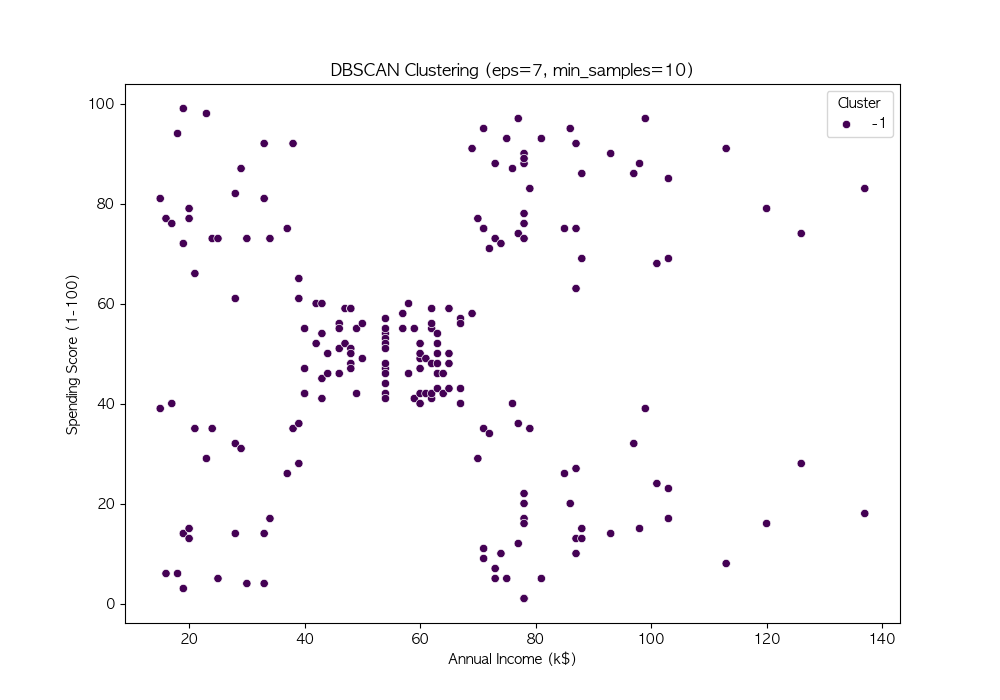
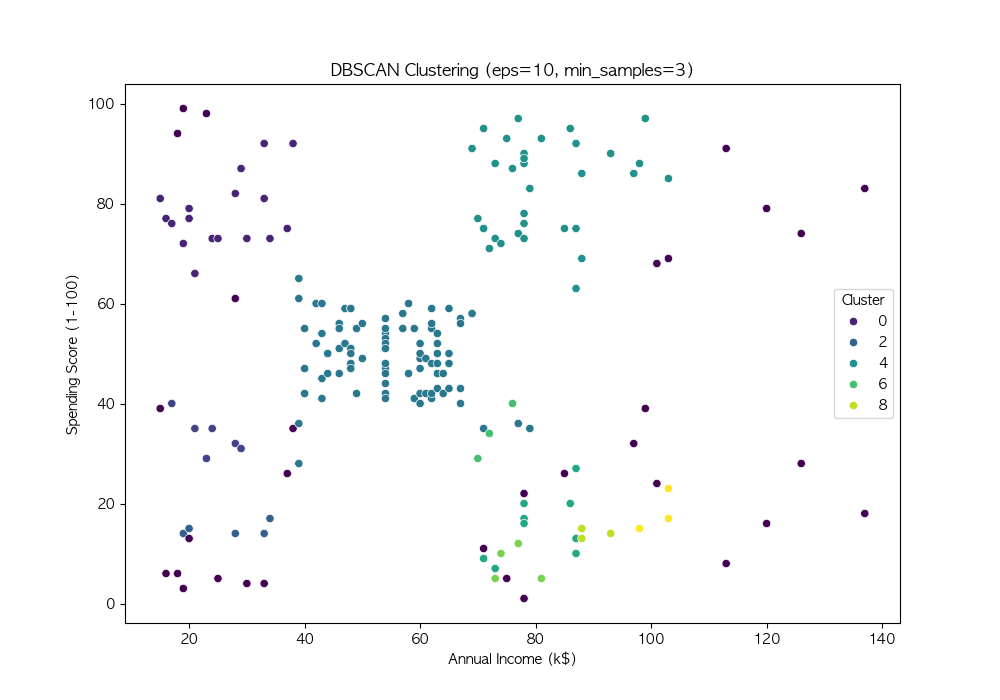
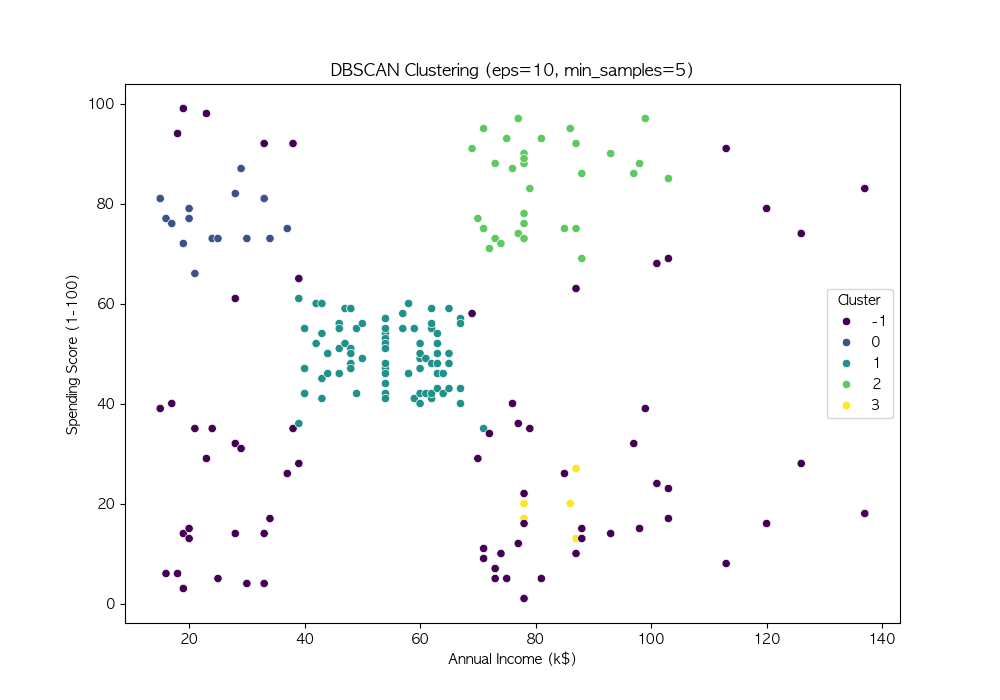
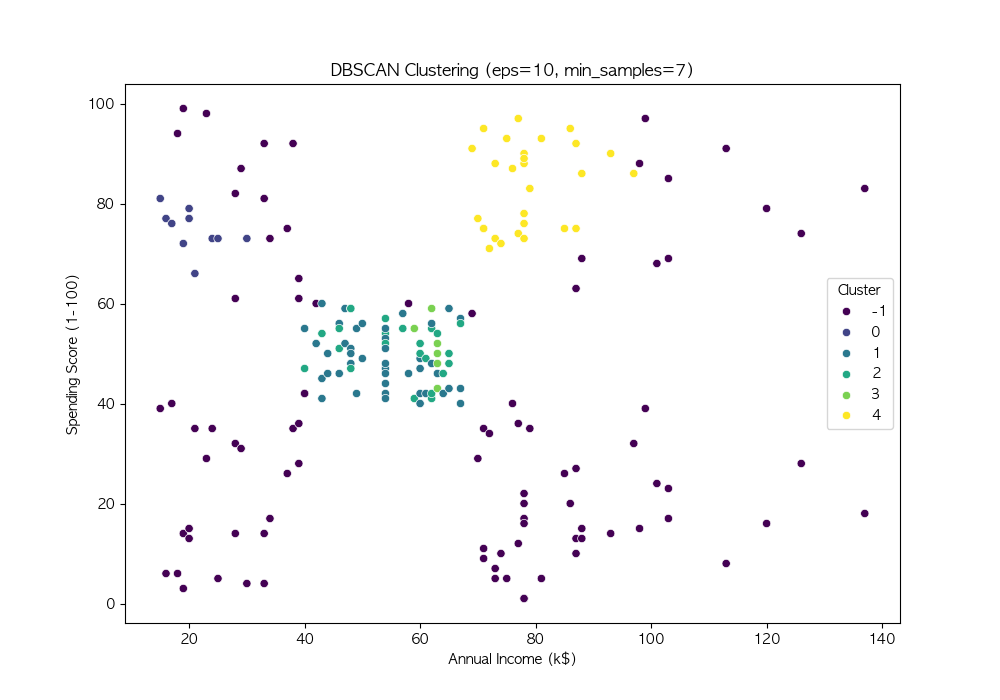
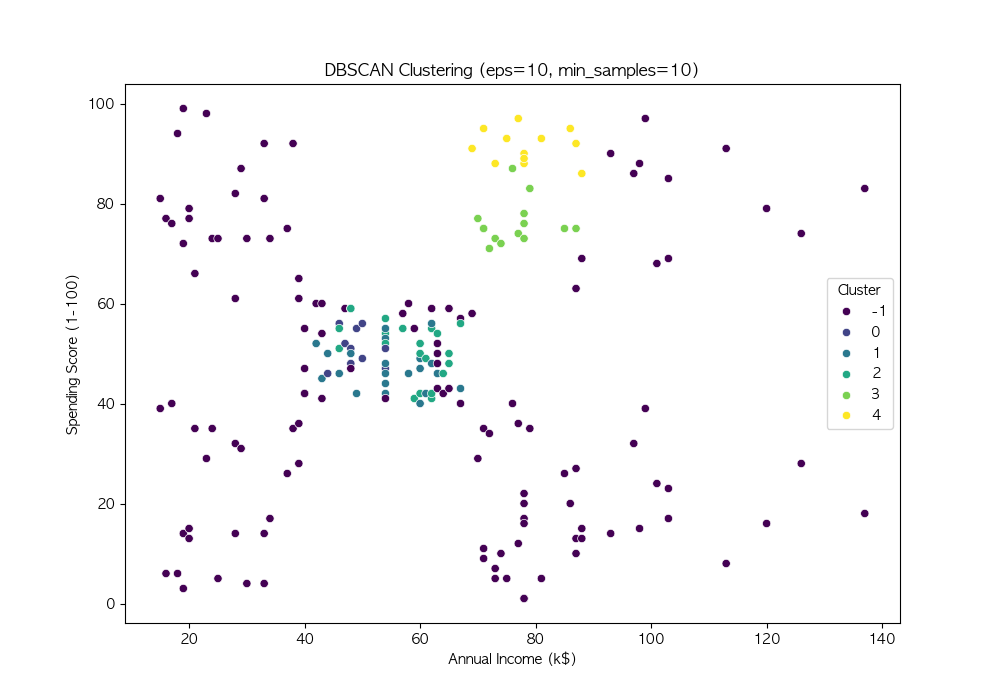
DBSCAN은 밀도 기반 군집화 기법 → 비구형 데이터에서도 효과적인 군집화 수행 가능
노이즈를 자동으로 탐지, 군집 개수를 사전에 설정할 필요가 없음 → 실전 데이터 분석에서 유용하게 활용 가능
DBSCAN의 성능은 eps와 min_samples 값에 따라 달라지므로, 적절한 하이퍼파라미터 튜닝이 필요
'⊢MachineLearning' 카테고리의 다른 글
| 비지도학습 : 차원축소 - t-SNE(t-Distributed Stochastic Neighbor Embedding) (2) | 2025.03.17 |
|---|---|
| 비지도학습 : 차원축소 - PCA(Principal Component Analysis, 주성분 분석) (0) | 2025.03.17 |
| 비지도학습 : 군집화 모델 - 계층적 군집화 (2) | 2025.03.17 |
| 비지도학습 : 군집화 모델 - k-means Clustering (3) | 2025.03.16 |
| 지도학습 : 분류모델 - 의사결정나무 (0) | 2025.03.16 |