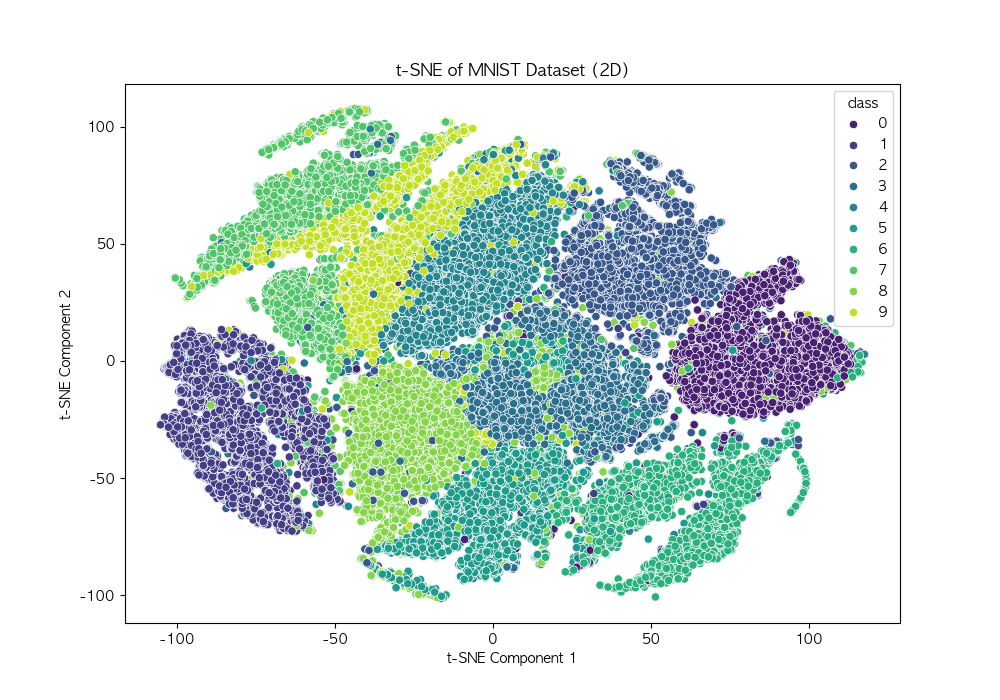
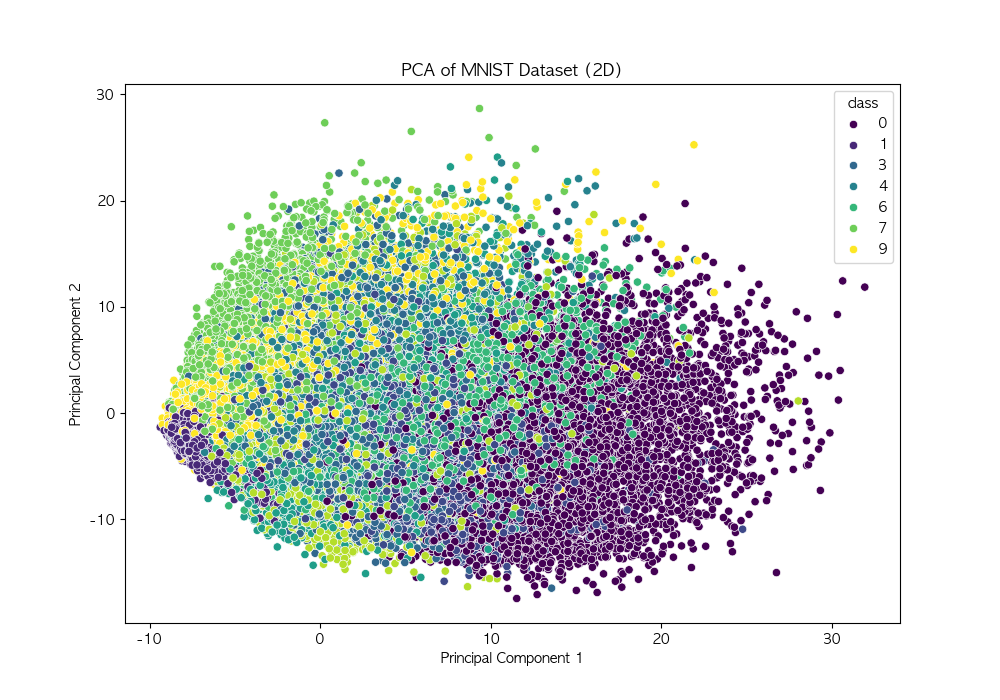
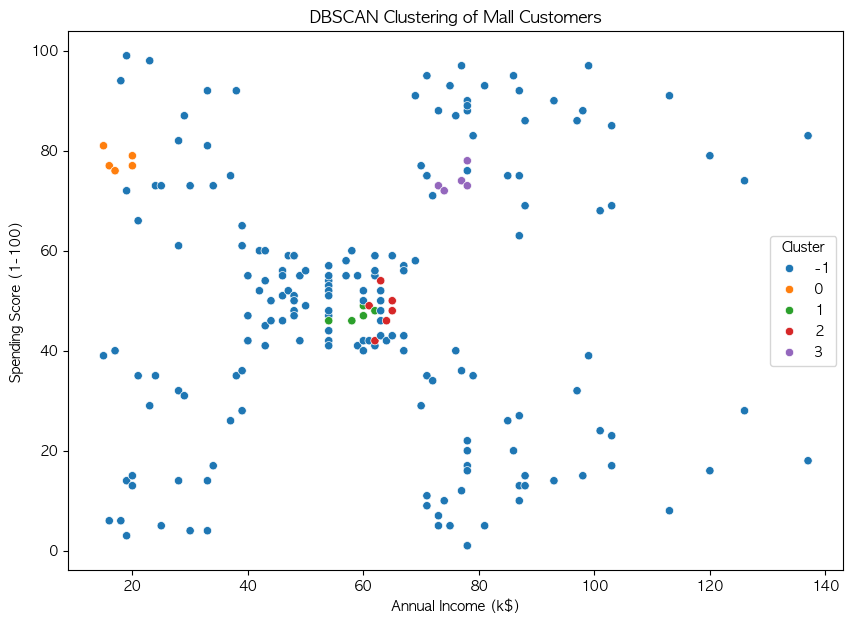
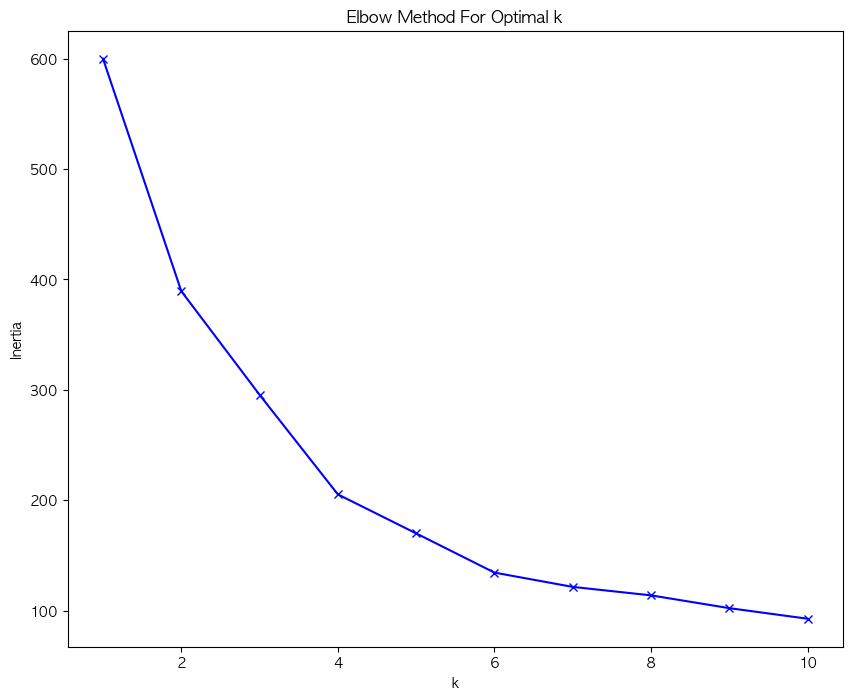
LDA (Linear Discriminant Analysis, 선형 판별 분석) 차원 축소와 분류를 동시에 수행하는 기법 클래스 간 분산을 최대화하고, 클래스 내 분산을 최소화하여 데이터를 변환저차원 공간에서 데이터의 구조를 유지하면서 분류 성능 향상 가능 작동 원리클래스별 평균 벡터 계산 : 각 클래스의 평균 벡터를 구함클래스 내 분산 행렬 계산 : 각 클래스 내부의 데이터 분산 계산클래스 간 분산 행렬 계산 : 클래스 평균 벡터 간의 분산을 구함고유값 및 고유벡터 계산 : 클래스 내 분산 행렬의 역행렬과 클래스 간 분산 행렬의 곱을 사용하여 고유값과 고유벡터 계산선형 판별 축 선택 : 고유값이 큰 순서대로 고유벡터를 정렬하여 주요한 선형 판별 축을 선택데이터 변환 : 선택된 판별 축을 사용하여 데이..