이상치(Outlier)
데이터의 일반적인 패턴에서 벗어난 값을 의미
=> 데이터 분석에 부정적인 영향을 미칠 수 있기 때문에, 탐지하고 적절히 처리하는 것이 중요
이상치 탐지 방법
기술 통계 기반 이상치 탐지
describe()함수 사용, 데이터의 기본 통계량 확인, 이상치 의심
import pandas as pd
#에시 데이터프레임 생성
data = {
'이름' : ['철수','영희','민수','지수','상수'],
'나이' : [25,30,22,35,120] #120은 이상치로 의심됨
'점수' : [90,85,95,80,88]
}
df = pd.DataFrame(data)
#기술 통계량 확인
df['나이'].describe()
평균(mean)과 표준편차(std)가 큰 차이를 보이는 경우, 또는 최대값(max)이 비정상적으로 높은 경우 이상치를 의심할 수 있음
시각화를 사용한 이상치 탐지
#박스플롯(Box Plot)과 히스토그램을 사용하면 데이터의 분포를 시각적으로 확인할 수 있어 이상치를 탐지하기 용이함
import matplotlib.pyplot as plt
#박스플롯으로 이상치 시각화
plt.boxplot(df['나이'])
plt.title('나이의 박스플롯')
plt.show()
IQR(Interquartile Range)를 사용한 이상치 감지
IQR은 1사분위수(Q1)와 3사분위수(Q3)의 차이로, 이 범위를 벗어나는 데이터를 이상치로 간주할 수 있음
#IQR 계산
Q1 = df['나이'].quantile(0.25)
Q3 = df['나이'].quantile(0.75)
IQR = Q3 - Q1
#IQR을 이용한 이상치 탐지
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df(df['나이'] < lower_bound) | [df['나이'] > upper_bound)
outliers
이상치 처리 방법
이상치 탐지 후, 데이터의 특성과 분석 목적에 따라 적절히 처리해야 함
이상치 제거
#이상치 제거한 데이터프레임
df_without_outliers =df[(df['나이'] >= lower_bound) & (df['나이'] <= upper_bound)]
df_without_outliers
이상치를 특정 값으로 대체
#'나이'의 중앙값으로 이상치 대체
median_age = df['나이'].median()
df['나이'] = df['나이'].apply(lambda x : median_age if x > upper_bound or x < lower_bound else x)
df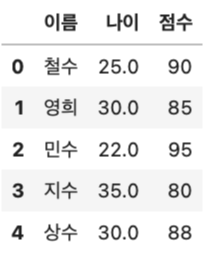
이상치를 그대로 유지
이상치가 중요한 분석 포인트가 될 수 있다고 판단되면, 별도의 처리를 하지 않고 그대로 유지할 수 있음
#이상치를 그대로 두는 경우(처리하지 않음)
df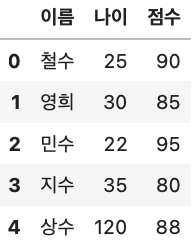
'Python to AI' 카테고리의 다른 글
| Python - 함수의 기본적 개념과 사용법 (6) | 2024.12.12 |
|---|---|
| Python - Pandas, Scikit-learn, SciPy(데이터 전처리 : 데이터 정규화와 표준화) (5) | 2024.12.11 |
| Python - Matplotlib 한글폰트 커스텀컨피그 (6) | 2024.12.10 |
| Python - Pandas(데이터 전처리 : isna(), isnull() ) (3) | 2024.12.10 |
| Python - Pandas(데이터 변형 : 그룹화, 집계, 피벗테이블) (4) | 2024.12.09 |