import pandas as pd
url = 'https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv'
#CSV파일 불러오기
df = pd.read_csv(url)
#상위 5개 행 미리보기
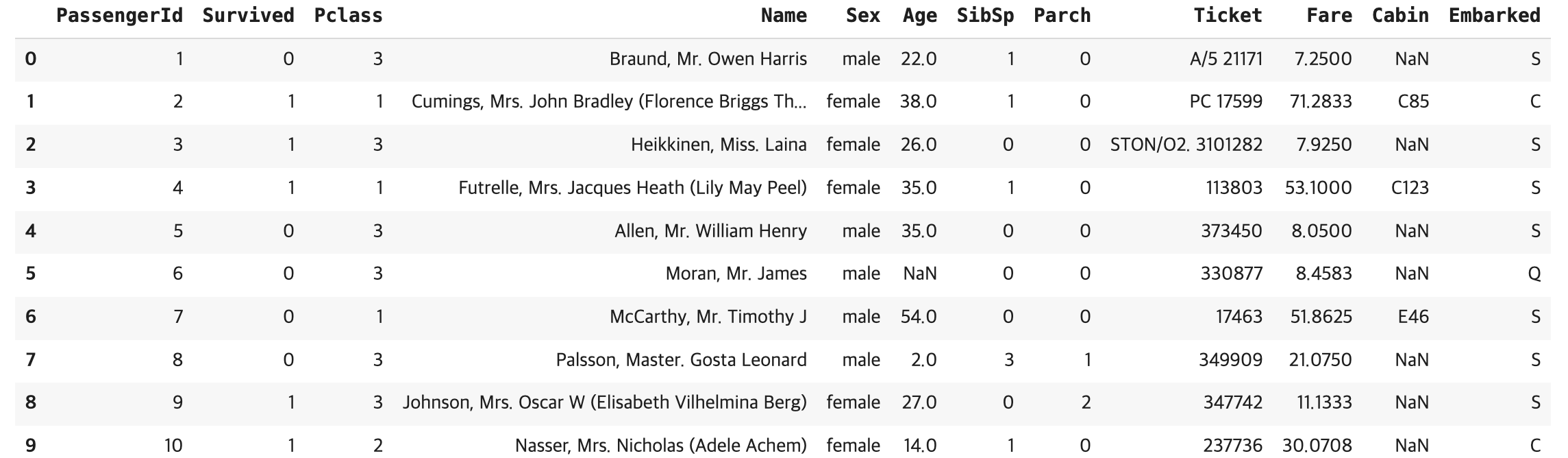
df.head()
#상위 10개 행 미리보기
df.head(10)
#하위 데이터 미리보기, 기본값(5개 행)
df.tail()
#하위 3개 행 미리보기
df.tail(3)
데이터프레임 기본 정보 확인
#info()함수 데이터프레임 전체 구조 각 열의 데이터 타입과 null값 여부 확인
df.info()
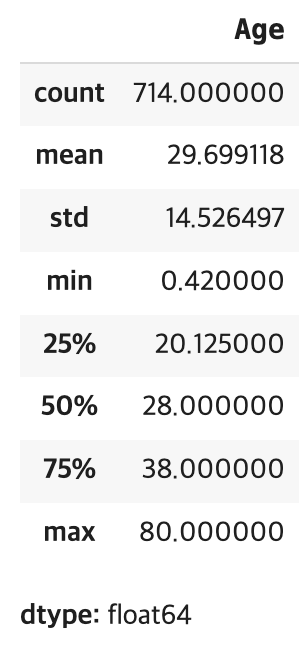
#describe() 주요 통계 정보 확인, 숫자형 데이터에 대한 주요 통계 정보 제공
df.describe()
#특정 열에 대한 통계
df['Age'].describe()
#columns와 index로 열과 행 정보 확인
print(df.columns) #열 이름 확인
print("\n",df.index) #행 인덱스 확인
#데이터프레임 개별 데이터 확인하기
#loc[] 라벨기반 인덱스 사용, 접근
#특정 행 조회
print(df.loc[0]) #첫 번째 행
#특정 행과 열 조회
print("\n","First row's Name Column Data: ",df.loc[0, 'Name']) #첫 번째 행의 '이름' 열 데이터
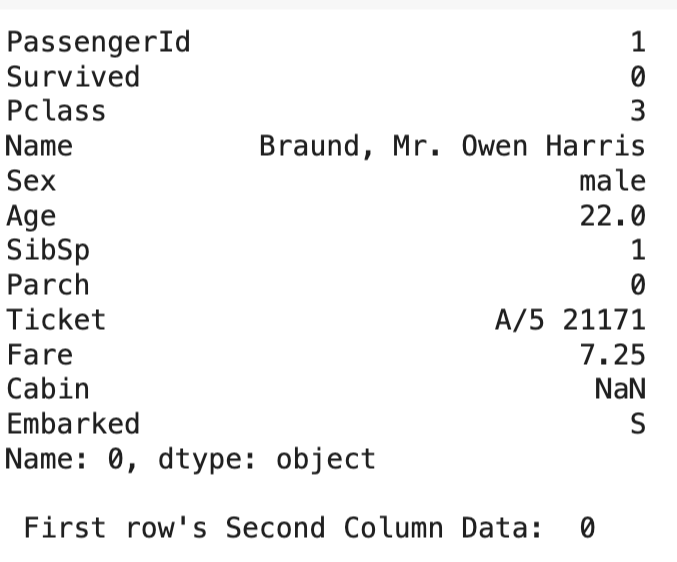
#iloc[]로 행과 열의 위치 인덱스 사용, 접근
#첫 번째 행 조회
print(df.iloc[0])
#첫 번째 행의 두 번째 열 데이터 조회
print("\n","First row's Second Column Data: ",df.iloc[0,1])