Pivot table
2개 이상의 기준으로 데이터를 집계할 때, 보기 쉽게 배열하여 보여주는 테이블
Pivot table의 기본 구조
| 구분 컬럼 | |
| 집계 기준 | 데이터 |
데이터 테이블들을 가지고 Pivot Table뷰를 만든다 -> Pivot View 구조를 만든다
예)
음식점별로 15시에서 20시까지 시간별 주문건수를 집계해본다.
1. 결제테이블에서 주문시간의 15시-20시의 시/분/초 중 시간만 SUBSTRING하고
2. 음식점명, 시간대를 기준으로 주문건수 데이터를 조회한다.
SELECT f.restaurant_name,
SUBSTRING(p.time, 1, 2) hh,
COUNT(1) cnt_order
FROM food_orders f INNER JOIN payments p ON f.order_id=p.order_id
WHERE SUBSTRING(p.time, 1, 2) BETWEEN 15 AND 20
GROUP BY 1, 2
첫째 컬럼에 음식점 명, 그리고 행은 각 음식점별 시간에 따른 주문건수를 집계하기위해
3. 제일 큰 SELECT문에 음식점명, 15-20까지의 컬럼을 만들어준다.
* 여기서 MAX의 기능
-> IF(hh='15', cnt_order, 0)를 통해서 hh가 15를 만족하면 cnt_order를, 그렇지 않은 경우에는 0로 반환
따라서 15시의 데이터를 제외한 모든 데이터는 0이 되기 때문에, MAX는 항상 cnt_order가 된다.
그리고 제일 큰 GROUP BY절에서 1(restaurant_name)이라고 작성하였기 때문에, 같은 음식점명을 가진 그룹내에서만 MAX와 IF문이 적용되고 다른 음식점명을 가진 데이터는 서로 간섭하지 않는다.
결론은 GROUP BY와 함께 사용하여 같은 그룹 내 데이터들만 가지고 조건에 부합하지 않는 value는 IF함수로 0으로 만들어버리고, 조건에 부합하는 value만 MAX함수로 뽑아내는거다.
4. 처음 만들었던 쿼리를 Subquery로 넣어주고 음식점명을 기준으로 묶어준다.
5. 원하는 순으로 정렬
SELECT restaurant_name,
MAX(IF(hh='15', cnt_order, 0)) "15",
MAX(IF(hh='16', cnt_order, 0)) "16",
MAX(IF(hh='17', cnt_order, 0)) "17",
MAX(IF(hh='18', cnt_order, 0)) "18",
MAX(IF(hh='19', cnt_order, 0)) "19",
MAX(IF(hh='20', cnt_order, 0)) "20"
FROM(
SELECT f.restaurant_name,
SUBSTRING(c.time, 1, 2) hh,
COUNT(1) cnt_order
FROM food_orders f INNDER JOIN payments p ON f.order_id=p.order_id
WHERE SUBSTRING(p.time, 1, 2) BETWEEN 15 AND 20
GROUP BY 1, 2
) t
GROUP BY 1
ORDER BY 7 DECS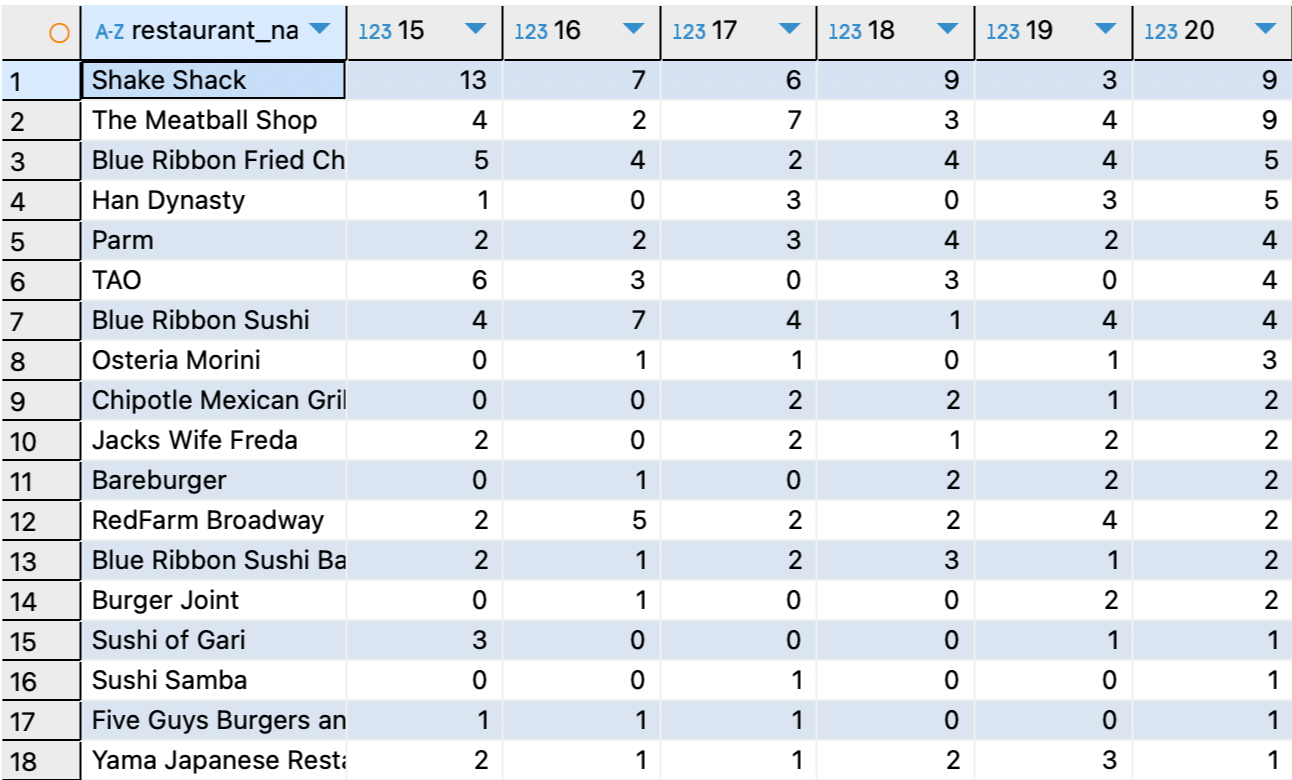
'SQL' 카테고리의 다른 글
| SQL - DATE_FORMAT (2) | 2024.12.02 |
|---|---|
| SQL - Window Function(RANK, SUM OVER) (6) | 2024.12.01 |
| SQL - 'Not given', NULL다루기 (0) | 2024.11.26 |
| SQL - JOIN(필요한 데이터가 서로 다른 테이블에 있을 때) (0) | 2024.11.26 |
| SQL - Subquery(여러번의 연산 수행) (2) | 2024.11.24 |