데이터프레임의 구조를 재조정
데이터를 원하는 형태로 변형
피벗(pivot), 변경(melt), 스택(stack), 언스택(unstack)
pivot()을 사용한 피벗 테이블 생성
pivot()함수는 열 데이터를 행 또는 열로 이동시켜 새로운 데이터프레임을 만듦
-데이터를 재구성하고 분석하는 데 매우 유용
import pandas as pd
#예시 데이터프레임 생성
data = {
'날짜' : ['2023-01-01', '2023-01-02', 2023-01-01', 2023-01-02'],
'도시' : ['서울', '서울', '부산', '부산'],
'온도' : [2, 3, 6, 7],
'습도' : [55, 60, 80, 85]
}
df = pd.DataFrame(data)
#'도시'를 기준으로 '날짜'를 인덱스로, '온도'를 값으로 하는 피벗 테이블 생성
pivot_df = df.pivot(index = '날짜', columns = '도시', values = '온도')
print(pivot_df)
melt()를 사용한 데이터 구조 해체
melt()함수는 피벗된 데이터를 다시 긴 형식(long format)으로 변환할 때 사용됨 - 여러 열을 하나의 열로 통합하는 데 유용
#데이터프레임 구조 해체(melt)
melted_df = pd.melt(df, id_vars = ['날짜','도시'], value_vars = ['온도', '습도']
melted_df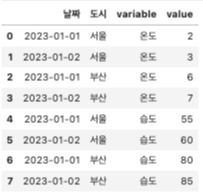
stack()과 unstack()을 사용한 데이터 변환
stack(): 열 데이터를 인덱스 하위 레벨로 이동
unstack(): 인덱스를 원래 구조로
-멀티 인덱스 데이터프레임에서 유용
#'도시'레벨을 인덱스로 스택(stack)
stacked_df = pivot_df.stack()
stacked_df
#언스택(unstack)하여 원래 구조로 복원
unstacked_df = stacked_df.unstack()
unstacked_df
stack(), unstack() 사용 시 주의 사항
-다중 인덱스의 필요
다중 인덱스가 없는 경우 stack()을 사용할 수 없음
unstack()은 행(Level)을 열로 변환 => DataFrame이 다중 인덱스를 갖고 있지 않으면 제대로 작동하지 않음
df = pd.DataFrame({'A': [1, 2]}, index=['X', 'Y'])
df.unstack() # ValueError 발생
-결과로 Series 반환
기본적으로 stack()은 데이터가 다중 인덱스로 구성된 Series를 반환
만약 DataFrame 형태를 유지하고 싶다면 추가작업 필요
stacked = df.stack()
stacked.to_frame() #DataFrame 형태로 변환
-결측치(Nan) 처리
stack()은 기본적으로 결측치가 있는 열은 제외 하고 변환
unstack()은 변환 과정에서 비어 있는 값이 있는 경우 자동으로 Nan으로 채움 => 데이터의 완결성을 확인해야 함
-level 파라미터
변환하고자 하는 열의 수준을 지정해야 할 경우, 다중 레벨의 열을 다룰 때 level 옵션에 주의
df = pd.DataFrame({
('A', 'x'): [1, 2],
('A', 'y'): [3, 4],
('B', 'z'): [5, 6],
}, index=['i', 'j'])
stacked = df.stack(level=0)
print(stacked)
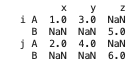
unstack() 시 특정 레벨의 인덱스만 열로 변환하려면 level을 정확히 지정해야 함
지정하지 않으면 기본적으로 가장 낮은 레벨이 선택됨
-정렬된 인덱스 필요
인덱스가 정렬되어 있지 않으면 stack()이나 unstack()이 제대로 작동하지 않을 수 있음
sort_index()를 사용해 정렬
df = df.sort_index() #stack/unstack 전에 정렬
데이터 프레임 크기 조정하기
행과 열의 추가, 삭제, 데이터 병합 등이 있음
데이터를 분석하기에 적합한 형태로 조정
행과 열 추가하기
새로운 열을 추가할 때는 새로운 데이터를 할당한다
df['새로운 열'] = 값
#새로운 열 추가
df['날씨'] = ['맑음', '흐림', '맑음', '흐림']
df
행과 열 삭제하기
drop()함수 사용
axis = 0 행
axis = 1 열
#'습도'열 삭제
df_dropped = df.drop(columns = ['습도'])
df_dropped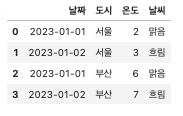
#특정 행 삭제(예: 첫번째 행)
df_dropped_row = df.drop(index=0)
df_drooped_row
| 특징 | drop | del |
| 사용 범위 | Pandas DataFrame, Series | Python 변수, Pandas DataFrame의 열 |
| 행(row) 삭제 | 가능(axis = 0) | 불가능 |
| 열(column) 삭제 | 가능(axis = 1) | 가능 |
| 원본 수정 여부 | 기본적으로 원본 유지(inplace = True로 수정 가능) | 항상 원본 수정 |
| 반환값 | 새로운 DataFrame 또는 Series | 반환값 없음 |
| 삭제 대상 | 이름(labels) 또는 인덱스(index) | 변수 또는 열 이름(컬럼만 가능) |
데이터 병합
concat()
merge()
#새로운 데이터프레임 생성
data2 = {
'날짜' = ['2023-01-03', '2023-01-04'],
'도시' = ['서울', '부산'],
'온도' = [5, 8],
'습도' = [70, 75],
'날씨' = ['맑음', '흐림']
}
df2 = pd.DataFrame(data2)
#행을 기준으로 데이터프레임 병합(concat)
merged_df = pd.concat([df, df2], ignore_index = True)
merged_df
=> 새로운 데이터가 병합되어 데이터프레임의 크기가 확장됨
| 특성 | concat | merge |
| 기능 | 단순 연결 | 관계를 고려한 병합(SQL JOIN) |
| 기준 | 인덱스 또는 축(axis) | 공통 열 또는 인덱스 |
| 결과 | 단순히 데이터 이어붙이기 | 기준에 따라 데이터를 병합 |
| 결과 형태 | 기존 구조를 유지 | 기준에 따라 새로운 구조 생성 |
| 병합 방식 | 단순 연결(inner, outer 없음) | inner, outer, left, right 지원 |
'Python to AI' 카테고리의 다른 글
| Python - Matplotlib (4) | 2024.12.30 |
|---|---|
| AI/ML/DL (3) | 2024.12.24 |
| Python - Pandas(다차원데이터관리 : MultiIndex) (4) | 2024.12.17 |
| Python - 객체 탐색과 속성 관리 (4) | 2024.12.15 |
| Python - Pandas(데이터 전처리: Encoding, Embedding) (5) | 2024.12.13 |